GitKraken Desktop
GitKraken Desktop GitLens for IDEs
GitLens for IDEs  GitKraken CLI
GitKraken CLI GitKraken MCP
GitKraken MCP GitKraken Insights
GitKraken Insights Dev Team Automations
Dev Team Automations AI & Security Controls
AI & Security Controls Git Integration for Jira
Git Integration for Jira Supercharge Your Dev Team
Supercharge Your Dev Team  Secure Your Dev Team
Secure Your Dev Team 

GitKraken is a React app. We’ve been using React since version 0.12.2 (in January of 2015) when we migrated from Angular.js. When we started using React, we architected with the flux library from Facebook as our state model and forged ahead into glory. At first, it was good. Much performance. Many code. Wow!
The initial excitement subsided, and the honeymoon was over. We looked back at our strange mess of state and decided to make a move to Redux. It’s fair to say we had problems scaling with Flux.
The GitKraken team is now finishing up the transition from Flux to Redux, and everything is looking really amazing. There are already a lot of benefits that we are seeing from Redux as we write new code for the application.
Redux vs Flux
For those unfamiliar with Redux, but familiar with Flux, you can think of Redux as a stricter implementation of Flux. Instead of multiple stores and a dispatcher to bind all of the stores together, there is one store that holds all of the state in the application.
For those unfamiliar with both libraries, the Flux library is the implementation of the Flux pattern. The Flux pattern is similar to Model View Controller (MVC), but has a strict one-way data flow constraint.
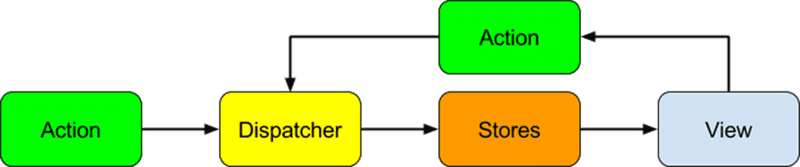
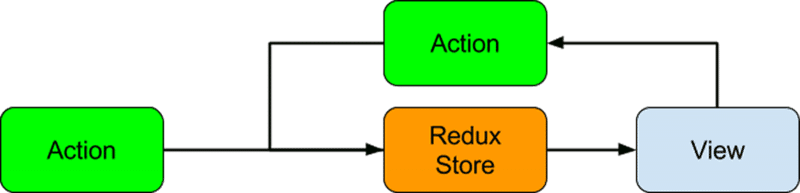
Flux pattern
At each step in the flow, data is limited to only one movement direction. A view can start an action at the request of a user, the action can generate new data and pass it to the dispatcher, the dispatcher dispatches the results of actions to the stores, and the stores can then emit an update to the views.
In the Redux library, we’ve reduced our total store count to one, and thus we don’t need a dispatcher at all. The dispatcher was originally there to manage the order in which we update stores with action results and keep the stores behaving. Instead, we just directly inform the Redux store of an action that has occurred. So we’ve kept the basic premise of the Flux pattern, but shrank the pattern’s flow by combining the dispatcher and the store.
Redux state
Since we only have one store now, my first reaction was that the store would be a monolithic hellspawn of a maintenance issue, but we actually keep some semblance of order by using Redux’s reducer pattern for our separating concerns. The main mechanism for Redux is the reducer pattern; we have one top level reducer, and we can branch substate trees into smaller reducers.
A reducer is a pure function of state and message to state. We take the previous state tree, a message, and apply some transformation of the state to produce a new state tree. The top level reducer has this shape, and any subreducers also have this shape.
The process of reducing utilizes a constraint we place on the Redux state, that it is immutable. When a message is passed into Redux land, the message is passed through a series of these reducers. Those reducers then decide whether or not to perform an update according to the message.
In our case, the reducers decide whether or not to produce a brand new object. To clarify, we update every reference along a path to an updated value, such that we have made no mutations to the previous state tree. When our reducers produce a brand new object, we know that changes happened to that particular substate tree. In fact, we can trace the new object references to the exact set of changes that have taken place between the previous state and the next state.
Benefits of Redux
What makes this transition so nice to work with is that exactly one message changes state at a time in a very consistent and straightforward manner (a → b). It might seem a bit daunting at first to hoist all state of the app into a single state tree, but the benefits are an amazing trade-off.
Things like time travel can be implemented in a trivial fashion (just store the sequence of state updates). Holding all state in an immutable data structure also allows React to, erm, react better! We can utilize referential transparency when the Redux store emits a change. React can perform a check before updating to see if the top level object reference has changed, and it if hasn’t, shortcircuit the entire rendering tree.
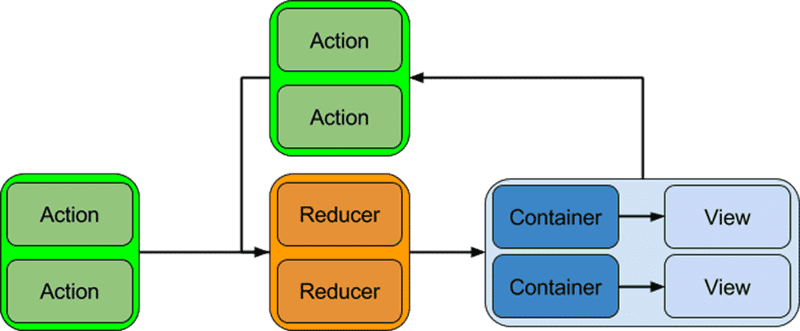
Another nice benefit of the pattern we build with Redux comes into play when we organize our view around our Redux state. We build containers which listen to Redux state, and when a state update occurs, those containers retrieve the relevant changes and choose whether or not to react. Those containers pass any state they care about to a presentation layer. These layers are largely stateless view components (components that only receive props).
Ok! Ok. The benefit I’m describing is that the view layer scales horizontally by top level containers, which hold onto a pure render tree. When we want to add more containers, we can do it in a clean manner (a container is responsible for a full view), even though every container talks to the same store. We’ve basically built an architecture that adds one connection per new UI container when scaling. That’s really clean!
That’s not the only place we scale better. The Redux state itself scales per reducer. We can grow the size of the total state by building new reducers with their own substate, but we don’t have to increase the complexity of already written reducers, nor do we have to manage an explicit dispatch order like we did in Flux. There’s only one store, and our reducers run synchronously, producing a new state one message at a time.
Scaling example
So there you have it. We have an architecture that now provides a cleaner scaling experience in GitKraken.